Abstract: BERT (Devlin et al., 2018) and RoBERTa (Liu et al., 2019) has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT. The construction of BERT makes it unsuitable for semantic similarity search as well as for unsupervised tasks like clustering. In this publication, we present Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT. We evaluate SBERT and SRoBERTa on common STS tasks and transfer learning tasks, where it outperforms other state-of-the-art sentence embeddings methods.
Authors: Nils Reimers and Iryna Gurevych 2019 (UKP-TUDA)
–
Paper Review
Introduction
- SBERT: modification of the BERT network using siamese and triplet networks that is able to derive semantically meaningful sentence embeddings.
- large-scale semantic similarity comparison, clustering, informaiton retrieval via semantic search
- BERT: uses a cross-encoder for sentence classificaion and sentence-pair regression tasks
- cross-encoder setup is unsuitable for various pair regression tasks due to too many possible combinations
- a common method to address clustering and semantic search is to map each sentence to a vector space such that semantically similar sentences are close -> average BERT output layer or use output of the first token (
[CLS]token) - but this method yiels bad sentence embeddings, often worse than average GloVe embeddings
- SBERT: alleviates issues addressed above by the siamese network architecture, which derivces fixed-sized vectors for input sentences
- Then using a similarity measure (e.g. Manhatten / Euclidean distance), semantically similar sentences can be found.
- Similarity measures are performed efficiently on modern hardware
- Fine-tuning SBERT
- Fine-tuned SBERT on NLI data outperforms SoTA embedding methods
- SBERT also achieves an improvement of 11.7 points on STS tasks
- SBERT can be adapted to a specific task
Related Work
BERT
- BERT: pre-trained transformer network
- Sentence-pair regression: two sentences separated by a special
[SEP]token - Multi-head attention over 12 or 24 layers is applied and the output is passed to a simple regression fucntion to derive the final label
- Sentence-pair regression: two sentences separated by a special
- Disadvantage: no independent sentence embeddings are computed, which makes it difficult to derive sentence embeddings from BERT
- Solutions: averaging outputs, using output of the special
CLStoken
- Solutions: averaging outputs, using output of the special
Sentence Embeddings
- Skip-Thought: encoder-decoder architecture trained to predict surrounding sentences
- InferSent: uses Stanford NLI dataset and Multi-Genre NLI dataset to train a siamese BiLSTM network with max-pooling over the output
- Universal Sentence Encoder: trains a transformer network and augments the unsupervised learning with training on SNLI
- SNLI datasets are suitable for training sentence embeddings
- Poly-encoders (Humeau et al., 2019): compute a score between $m$ context vectors and pre-computed candidate embeddings using attention
- works for finding the highest scoring sentence in a larger collection
- drawback: score function is not symmetric and the computational overhead is too large for use-cases like clustering
- SBERT: use pre-trained BERT and RoBERTa network and only fine-tune it to yield useful sentence embeddings
- significantly reduces training time
- SBERT can be tuned in less than 20 minutes
Model
Architecture
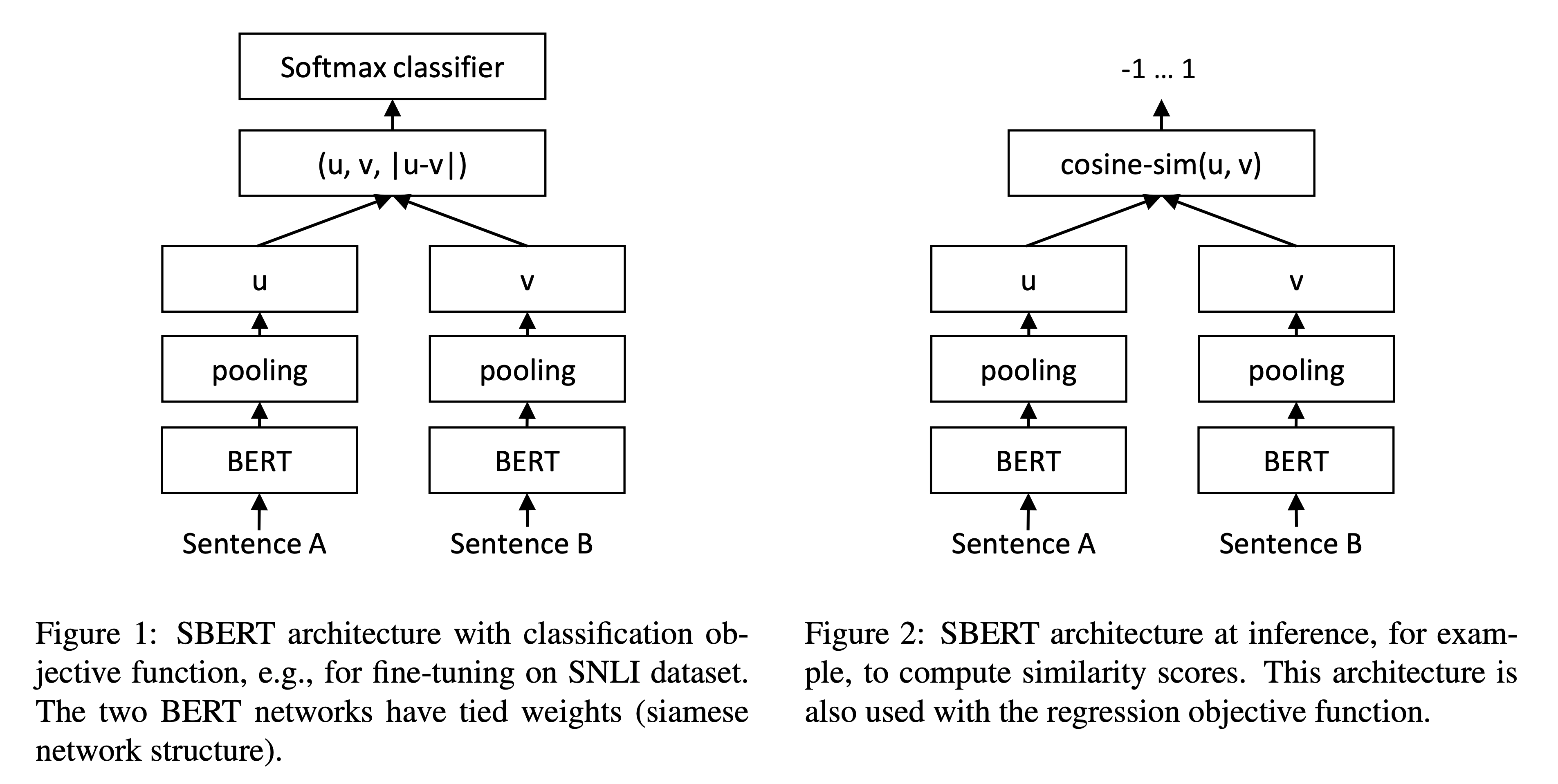
- SBERT adds a pooling operation to the output of BERT/RoBERTa to derive a fixed size sentence embedding
- Three pooling strategies
- Ouput of
CLStoken - Mean of all output vectors (
MEANstrategy) is default config - max-over-time of the ouput vectors (
MAXstrategy)
- Ouput of
- Three pooling strategies
- In order to fine-tune BERT / RoBERTa, we create siamese and triplet networks (Schroff et al., 2015) to update the weights such that the produced sentence embeddings are semantically meaningful and can be compared with cosine-similarity.
- Network structure depends on the available training data.
- Objective Functions
- Classificaion Objective Function: concat sent embeddings $u$ and $v$ with element-wise difference $|u-v|$ and multiply it with trainable weight $W_{t} ∈ R^{3n x k}$ where $n$ is the dimension of the sentence embeddings and $k$ the number of labels. We optimize cross-entropy loss.
- Regression Objective Function: cosine-similarity between two sentence embeddings $u$ and $v$ is computed. We use mean-squared-error loss as the objective function
- Triplet Objective Function: Given an anchor sentence $a$, a positive sentence $p$, and a negative sentence $n$, triplet loss tunes the network such that the distance between $a$ and $p$ is smaller than the distance between $a$ and $n$.
Training Details
- Training Data: SNLI, Multi-Genre NLI dataset
- Fine-tune with 3-way softmax-classifier objective function for one epoch
- We used a batch-size of 16, Adam optimizer with learning rate 2e 5, and a linear learning rate warm-up over 10% of the training data. Our default pooling strategy is
MEAN.
Evaluation - STS
- Unlike other SoTA methods that learns a regession function that maps sentence embeddings to a similarity score, SBERT always uses cosine-similarity to compare the similarity between two sentence embeddings.
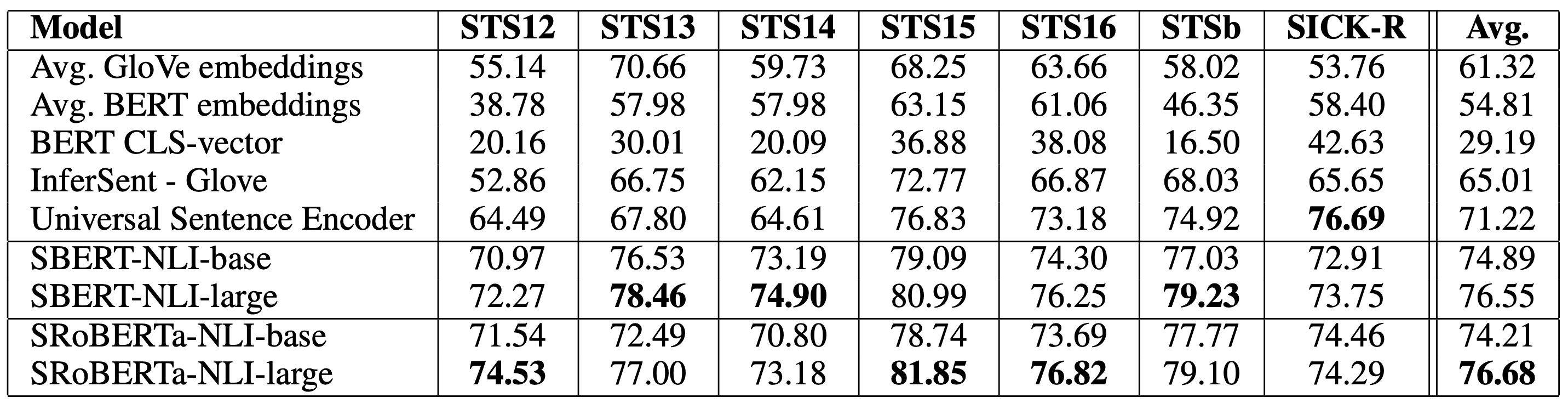
Unsuperivsed STS
- evaluate SBERT on STS without using any STS specific training data
- Compute Spearman’s rank correlation btwn the cosine-similarity of the sentence embeddings and the gold labels (Pearson correlation is badly suited for STS)
- Directly using output of BERT leads to poor performance
- SBERT outperforms correlation rank
- Minor difference between SBERT and SRoBERTa for sentence embeddings

Supervised STS
- Use training set of STSb to fine-tune SBERT using the regression objective function
- Only training on STSb
- First training on NLI, then traiing on STSb
- latter strategy leads to slight improvement of 1-2 points
- No significant difference between BERT and RoBERTa
Argument Facet Similarity
- Argument Facet Similarity (AFS) corpus by Misra et al. (2016): annotated 6,000 sentential argument pairs from social media dialogs on three controversial topics: gun control, gay marriage, and death penalty
- data annotated on scale of 0 (“different topic”) to 5 (“completely equivalent”)
- argumentative excerpts from dialogs: to be similar, arguments must not only make similar claims, but also provide a similar reasoning
- lexical gap between sentences in AFS is much larger, which is why unsupervised methods perform badly on this dataset
- Two evaluation methods
- Result: not as good as BERT; seems task is more complicated
Wikipedia Sections Distinction
- Dor et al. (2018) use Wikipedia to create a thematically fine-grained train, dev and test set for sentence embeddings methods.
- assumes that sentences in the same section are thematically closer than sentences in different sections
- sentence triplets: anchor, positive example, negative example
- Use Triplet Objective to train for one epoch
- Result: SBERT outperforms BiLSTM approach by Dor et al.
5 Evaluation - SentEval
- SentEval: toolkit to evaluate the quality of sentence embeddings
- Sentence embeddings are used as features for a logistic regression classifier. The logistic regression classifier is trained on various tasks in a 10-fold cross-validation setup and the prediction accuracy is computed for the test-fold.
- Although SBERT is not meant to be used for transfer learning for other tasks, we think SentEval can still give an impression on the quality of our sentence embeddings for various tasks
- SBERT tested on seven SentEval transfer tasks
- SBERT manages to achieve best performance in 5 our of 7 tasks
- It seems SBERT captures sentiment information (large improvements for all sentiment tasks)
- Does worse on TREC dataset, which is a question-type classification task
Ablation Study
- Evaluate different pooling strategies:
MEAN,MAX,CLS - For the classification objective function, evaluate different concatenation methods
- pooling strategy has rather minor impact
- concatenation mode impact is much larger
- most import component is $| u - v |$
- element-wise difference measures the distance between the dimensions of the two sentence embeddings, ensuring that similar pairs are closer and dissimilar pairs are further apart
- Regression objective function, pooling strategy has large impact
MAXperforms signficantly worse thanMEANorCLS-token strategy, in contrast to Conneau et al. (2017) who foundMAXbeneficial for BiLSTM-layer of InferSent
Computational Efficiency

My Thoughts
- SBERT knowledge distillation 논문은 자세히 읽었었는데 막상 본 SBERT 논문을 끝까지 읽은 건 오늘 처음인 것 같다… ㅎㅎ
- 아이디어 자체는 예전 논문에서 가져와서 BERT와 RoBERTa에 적용한 것. Siamese Network를 처음으로 설계한 논문도 읽어보고 싶어졌다. 그리고 cross-encoder이랑의 차이가 정확히 뭔지 알고 싶다.
- Task에 따라서 objective function을 새로 설계한 점도 인상적. 지금 내가 하고 있는 summarization 테스크에도 적용할 수 있는 objective function이 있을까?
- 놀랍게도 업계에서 좀 fact처럼 받아드려졌던 CLS 토큰의 사용 방법은 옳지 않다는 것을 증명한 논문이라는 점에서도 의의가 있는 것 같다. 사실 우리는 이 트랜스포머 안에서 도대체 무슨 일이 일어나고 있고 웨이트가 도대체 뭘 배우고 있는 건지 모른다는 걸 증명하기도 한다… ㅎㅎ