Abstract: We present an easy and efficient method to extend existing sentence embedding models to new languages. This allows to create multilingual versions from previously monolingual models. The training is based on the idea that a translated sentence should be mapped to the same location in the vector space as the original sentence.
–
Paper Summary
Goal: present a method to make a monolingual sentence embeddings method multilingual with aligned vector spaces between the languages.
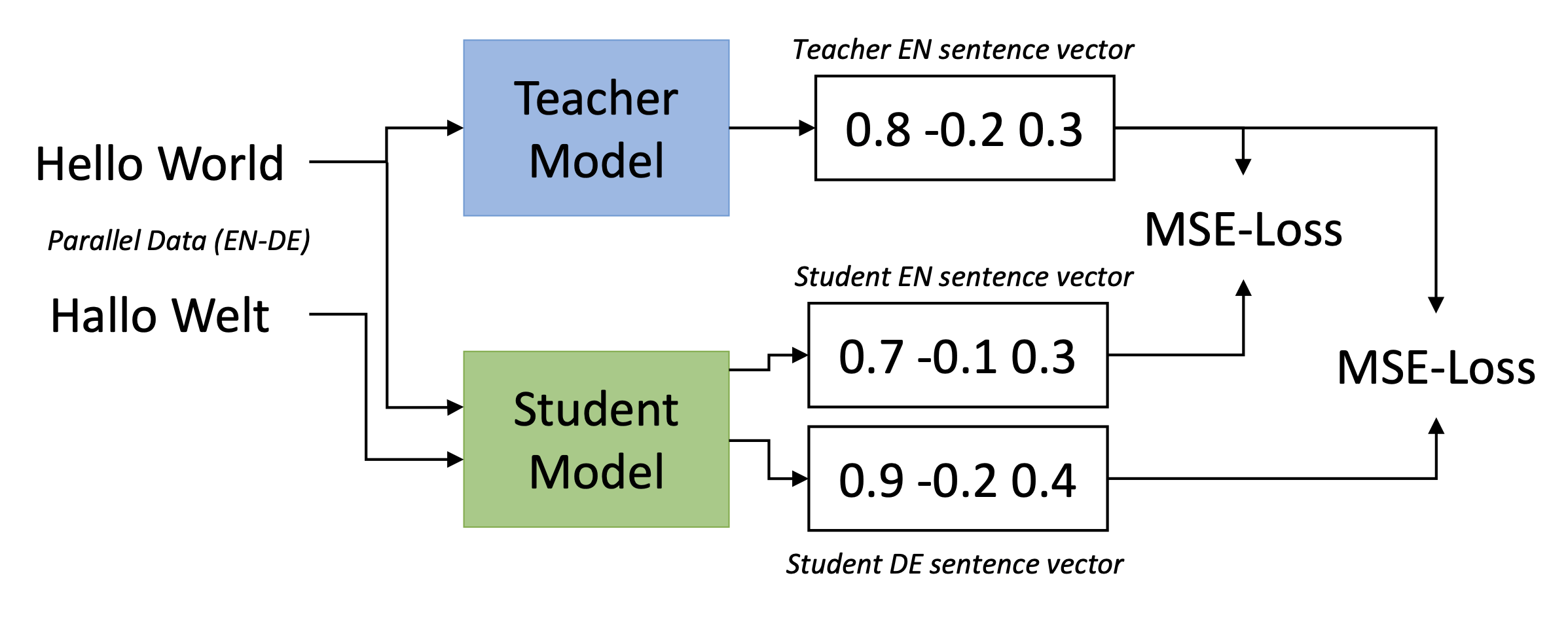
Method: using multilingual knowledge distillation
• Teacher model M for source language s and a set of parallel (translated) sentences ((s_1, t_1), …, (s_n, t_n)) with t_i the translation of s_i (t_i can be different languages)
• We train a new student model ˆM such that ˆM (s_i) ≈ M (s_i) and ˆM (t_i) ≈ M (s_i) using mean squared loss.
• Teacher Model: SBERT
• Student Model: XML-RoBERTa b/c uses SentencePiece, which avoids language specific pre-processing & uses a vocabulary with 250k entries from 100 different languages.
• Training Data: The OPUS website (Tiede- mann, 2012) provides parallel data for hundreds of language pairs.
Task:
(1) Multilingual Semantic Textual Similarity: assign for a pair of sentences a score indicating their semantic similarity. Score of 0 indicates not related and 5 indicates semantically equivalent.
• Outperforms existing model using extended multilingual STS 2017 dataset
(2) Bitext Retrieval: identifies parallel (translated) sentences from two large monolingual corpora. Given two corpora in different languages, the task is to identify sentence pairs that are translations.
• use the Building and Using Comparable Corpora (BUCC) bitext retrieval code from LASER
• use the dataset from the BUCC mining task • Does not outperform LASER and mUSE
• Why? LASER was trained on translation data, hence works well to identify perfect translations. However, it performs less well for STS. SBERT-nli-stsb works well to judge STS, but has difficulties distinguishing between translations and non-translation pairs with high similarities. + problems with BUCC dataset construction
Evaluation of Training Datasets:
• Bilingual models are slightly better than the model trained for 10 languages -> curse of multilinguality, where adding more languages to a model can degrade the performance as the capacity of the model remains the same.
• We conclude that for similar languages, like English and German, the training data is of minor importance. Already small datasets or even only bilingual dictionaries are sufficient to achieve a quite high performance.
• For dissimilar languages, like English and Arabic, the type of training data is of higher importance. Further, more data is necessary to achieve good results.
My Thoughts
- A really simple but innovative way to apply transfer learning
- Advantageous in that you can utilize a variety of pre-trained models for the teacher/student models
- Interesting that the curse of multilinguality also applies to these models. If XLM-R is chosen as the student model and is trained with one specific language and shows moderate performance, is that overcoming the curse of multilinguality? Will the student model be able to overcome the curse of multilinguality by applying the same techniques as the authors of XLM-R? (increasing model size etc.)
- Again, importance of good data!!