Abstract: Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its complexity from O(L2) to O(LlogL), where L is the length of the sequence. Furthermore, we use reversible residual layers instead of the standard residuals, which allows storing activations only once in the training process instead of N times, where N is the number of layers. The resulting model, the Reformer, performs on par with Transformer models while being much more memory-efficient and much faster on long sequences.
Authors: Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 2020
–
Paper Summary
Introduction
Issue: To yield state-of-the-art results using the Transformer architecture, researchers have resorted to training ever larger Transformer models. The number of parameters exceeds 0.5B per layer in the largest configuration reported in (Shazeer et al., 2018) while the number of layers goes up to 64 in (Al-Rfou et al., 2018). These large-scale long-sequence models yield great results but strain resources to the point where some argue that this trend is breaking NLP research. Many large Transformer models can only realistically be trained in large industrial research laboratories and such models trained with model parallelism cannot even be fine-tuned on a single GPU as their memory requirements demand a multi-accelerator hardware setup even for a single training step.
Question: Do large Transformer models fundamentally require such huge resources or are they simply inefficient?
- Major sources of memory use in Transformer:
- Memory in a model with N layers is N -times larger than in a single-layer model due to the fact that activations need to be stored for back-propagation.
- Since the depth $d_f_f$ of intermediate feed-forward layers is often much larger than the depth d_model of attention activations, it accounts for a large fraction of memory use.
- Attention on sequences of length $L$ is $O(L^2)$ in both computational and memory complexity, so even for a single sequence of 64K tokens can exhaust accelerator memory.
Solution: Reformer model, using these techniques
- Reversible layers, first introduced in Gomez et al. (2017), enable storing only a single copy of activations in the whole model, so the N factor disappears.
- Splitting activations inside feed-forward layers and processing them in chunks removes the $d_f_f$ factor and saves memory inside feed-forward layers.
- Approximate attention computation based on locality-sensitive hashing replaces the $O(L^2)$ factor in attention layers with $O(L \log L)$ and so allows operating on long sequences.
Locality-Sensitive Hashing Attention
- Dot-Product Attention: standard attention used in Transformers
$Attention(Q,K,V) = softmax({\frac{QK^T}{\sqrt{d_k}}})V$
- Multi-head Attention: In the Transformer, instead of performing a single attention function with d_model-dimensional keys, values and queries, one linearly projects the queries, keys and values h times with different, learned linear projections to d_k , d_k and d_v dimensions, respectively.
- Attention is applied to each of these projected versions of queries, keys and values in parallel, yielding d_v - dimensional output values.
- These are concatenated and once again projected, resulting in the final values.
- Memory-efficient attention:
- Assume that Q, K and V all have the shape [batch size, length, d_model]
- The main issue is the term $QK^T$, which has the shape [batch size, length, length]. (With long sequences, even with batch-size 1, the matrix is very large)
- But it is important to note that the $QK^T$ matrix does not need to be fully materialized in memory.
- The attention can indeed be computed for each query $q_i$ separately and then re-computing it on the backward pass when needed for gradients. This way of computing attention may be less efficient but it only uses memory propor- tional to length.
- Where do Q, K, V come from?
- To build Q, K and V from A, the Transformer uses 3 different linear layers projecting A into Q, K and V with different parameters.
- For models with LSH attention, we want queries and keys (Q and K) to be identical. This is easily achieved by using the same linear layer to go from A to Q and K, and a separate one for V.
- We call a model that behaves like this a shared-QK Transformer.
- Hashing Attention:
- For the LSH attention, we start with two tensors, Q=K and V of the shape [batch size, length, d_model].
- Note that we are actually only interested in softmax(QK T ). Since softmax is dominated by the largest elements, for each query q_i we only need to focus on the keys in K that are closest to q_i. In our case, we actually only require that nearby vectors get the same hash with high probability and that hash-buckets are of similar size with high probability.
- We achieve this by employing random projections known as the LSH scheme
- LSH computes a hash function that matches similar vectors together, instead of searching through all possible pairs of vectors
- LSH attention: formalizing the LSH attention
- In the figure below, different colors depict different hashes, with similar words having the same color.
- When the hashes are assigned, the sequence is rearranged to bring elements with the same hash together and divided into segments (or chunks) to enable parallel processing.
- Attention is then applied within these much shorter chunks (and their adjoining neighbors to cover the overflow), greatly reducing the computational load.

- With hashing, there is always a small probability that similar items nevertheless fall in different buckets. This probability can be reduced by doing multiple rounds of hashin
Reversible Transformer
- RevNets: allow the activations at any given layer to be recovered from the activations at the following layer, using only the model parameters. Rather than having to checkpoint intermediate values for use in the backward pass, layers can be reversed one-by-one as back-propagation proceeds from the output of the network to its input.
- Reversible Transformer: We apply the RevNet idea to the Transformer by combining the attention and feed-forward layers inside the revnet block.
- The reversible Transformer does not need to store activations in each layer
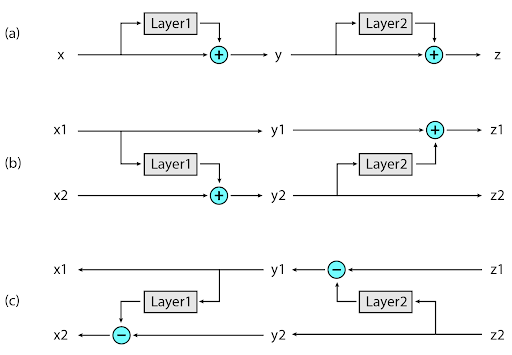
- The reversible Transformer does not need to store activations in each layer
- Chunking: computations in feed-forward layers are completely independent across positions in a sequence, so the computation can be split into c chunks
Experiments
- Tasks: imagenet64 and enwik8-64K
- Setup:
- 3-layer models for ablations
- d_model = 1024
- d_ff = 4096
- n_heads = 8
- batch size = 8
- optimizer: Adafactor
- device = 8 devices (8 GPUs or 8 TPU v3 cores)
- Effects:
- sharing QK: does not perform worse than regular attention; in fact, for enwik8 it appears to train slightly faster. In other words, we are not sacrificing accuracy by switching to shared-QK attention.
- reversible layers: memory savings in the reversible Transformer do not come at the expense of accuracy.
- LSH attention: LSH attention is an approximation for full attention that, as evidenced in Figure 4, becomes more accurate as the number of hashes increases.
- The computational cost of a model grows with the number of hashes, so this hyperparameter can be adjusted depending on the available compute budget
- Large Reformer models: we train up to 20-layer big Reformers on enwik8 and imagenet64. As can be seen in Figure 5, these models fit into memory and train.


My Thoughts
- 나 같은 대학원생이 자주 부딪히는 문제이다. 지긋지긋한 CUDA OOM 에러 ㅎㅎ 이 저자들은 구글에서 막대한 리소스를 사용하면서 진행한 연구이기 때문에 사실 좀 의심이 되긴한데… 게다가 task 실험에는 무려 TPU 8개를 사용하면서 했다니! 자원을 아껴가며 진행한 실험은 아닌 거 같다. ㅋㅋ 실제로 내가 GPU 4개에 돌려보면서 OOM 에러, data parallelization 에러가 발생하지 않는지 확인해봐야 완전히 믿을 수 있을 거 같다.
- 논문이 조금 어려워서 이해하면서 읽는데 좀 오래 걸렸지만 온라인 블로그에 더 쉽게 나와있는 설명을 참고하며 읽으니 이해에 도움이 되었다. Hashing을 어텐션 메커니즘에 옮긴 생각을 하고 실행한 것도 대단하지만 사실 난 reversible transformer 아이디어가 더 대단한거 같다. 왜냐하면 아이디어는 너무 간단하기 때문에. 필요한 activation을 다 저장하지 말고, 조금 더 효율성이 떨어져도 그냥 그때 그때 소수 레이어의 activation을 보관하는 모델을 만든다는 게 정말 간단하면서 효율이 엄청 올라갈 것만 같다. RevNet이라는 논문에서 처음 적용한 거 같은데, 나중에 시간이 되면 이것도 한 번 찾아봐야겠다.
NLP 분야에는 사실 데이터양이 비전만큼 많지 않기 때문에 비전이나 다른 AI 필드에 적용된 방법들을 가져와서 결합하는 경우가 많다. GAN도 그렇고… 또 생각나는 게 없는데 어쨋든 많다. 논문을 많이 읽을 수록 NLP 외에 다른 분야에서의 최근 실험 논문을 더 많이 읽어야겠다는 생각이 든다. 흐름이 거의 VISION -> NLP -> NLSP 이렇게 흘러 가는 거 같다.
- 요즘 논자시 시험도 준비하고, 이것 저것 신경 쓸일이 많아서 (핑계지만) 블로그를 좀 소홀히 쓰게 된다. 내가 코드 구현한 것도 더 많이 올리고 싶은데 쉽지가 않다 ㅠㅠ 앞으로 혼자 진행할 수 있는 간단한 프로젝트라도 찾아봐서 한 달에 한 번은 그런 코드 포스팅으로 하려고 노력을 해야겠다.