About GPT
Text Generation에 크게 관심이 없었기 때문에 GPT에 대해서 그냥 Autoregressive한 모델이구나… generation에 쓰이구나… 정도만 알고 있었다. 근데 최근 과제 주제를 Chatbot으로 잡았기 때문에 논문을 읽기 시작했다. 먼저 GPT는 Open AI에서 개발한 Transformer기반 Autoregressive 모델이고 2018년 부터 2020년까지 GPT-1, GPT-2, GPT-3가 공개되었다. 이 모델들을 기반으로 DialoGPT 라는 챗봇 중심 모델도 2019년에 개발되었다. 오늘은 GPT-1을 제외한 GPT-2, GPT-3 논문을 간략히 요약할 예정이다. DialoGPT는 다음 포스트에서…
앞서 대략 GPT의 goal을 요약하자면 zero-shot transfer learning을 가능하게 하는 것이다. Fine-tuning 프로세스를 제거하는 것이 궁극적은 목표라고 볼 수 있다. 이에는 여러 이유가 있지만 가장 큰 이유는 더 general NLP model에 도달하기 위해서이다. 부가적인 이유로는 데이터 레이블링을 감수하지 않아도 되는 편리함, 학습 데이터 분포 또는 오류에 영향을 받지 않는 모델 개발 등이 있겠다.
GPT-2: Language Models are Unsupervised Multitask Learners (2019)
Abstract: Natural language processing tasks, such as question answering, machine translation, reading com- prehension, and summarization, are typically approached with supervised learning on task-specific datasets. We demonstrate that language models begin to learn these tasks without any explicit supervision when trained on a new dataset of millions of webpages called WebText. When conditioned on a document plus questions, the answers generated by the language model reach 55 F1 on the CoQA dataset - matching or exceeding the performance of 3 out of 4 baseline systems without using the 127,000+ training examples. The capacity of the language model is essential to the success of zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. Our largest model, GPT-2, is a 1.5B parameter Transformer that achieves state of the art results on 7 out of 8 tested language modeling datasets in a zero-shot setting but still underfits WebText. Samples from the model reflect these improvements and contain co- herent paragraphs of text. These findings suggest a promising path towards building language processing systems which learn to perform tasks from their naturally occurring demonstrations.
Approach
- Language Modeling: unsupervised distribution estimation
Why Language Modeling?
Learning to perform a single task can be expressed in a probabilistic framework as estimating a conditional distribution $p(output input)$. - Since a general system should be able to perform many different tasks, even for the same input, it should condition not only on the input but also on the task to be performed.
That is, it should model $p(output input, task)$ <– main idea
- Language modeling is also able to, in principle, learn the tasks of McCann et al. (2018) without the need for explicit supervision of which symbols are the outputs to be pre- dicted.
- Since the supervised objective is the the same as the unsupervised objective but only evaluated on a subset of the sequence, the global minimum of the unsupervised objective is also the global minimum of the supervised objective.
- The problem becomes whether we are able to, in practice, optimize the unsupervised objective to convergence
Training Dataset
- WebText: a new web scrape which emphasizes document quality. To do this we only scraped web pages which have been curated/filtered by humans. Manually filtering a full web scrape would be exceptionally expensive so as a starting point, we scraped all outbound links from Reddit, a social media platform, which received at least 3 karma. This can be thought of as a heuristic indicator for whether other users found the link interesting, educational, or just funny.
Input Representation
- Byte Pair Encoding (BPE): (Sennrich et al., 2015) is a practical middle ground between character and word level language modeling which effectively interpolates between word level inputs for frequent symbol sequences and character level inputs for infrequent symbol sequences.
- we prevent BPE from merging across character categories for any byte sequence (prevents many versions of common words like
dog. dog! dog?)
- we prevent BPE from merging across character categories for any byte sequence (prevents many versions of common words like
Model
- OpenAI GPT Model with few modifications
- Layer normalization (Ba et al., 2016) was moved to the input of each sub-block, similar to a pre-activation residual network (He et al., 2016) and an additional layer normalization was added after the final self-attention block.
- A modified initialization which accounts for the accumulation on the residual path with model depth is used. We scale the weights of residual layers at initialization by a factor of $1/ sqrt(N)$ where N is the number of residual layers.
- The vocabulary is expanded to 50,257. We also increase the context size from 512 to 1024 tokens and a larger batchsize of 512 is used.
Experiments
- small, medium large models
- tuned for best preplexity on a 5% held-out sample of WebText
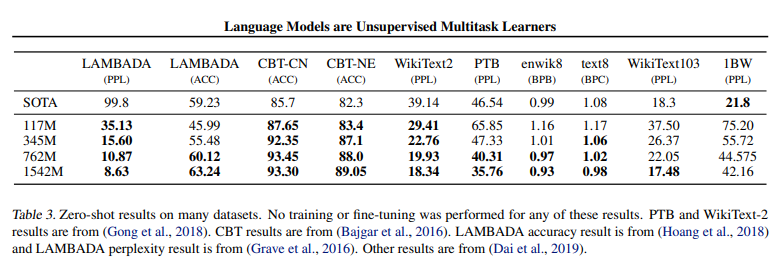
Generalization vs. Memorization
- As the size of datasets increases verlap between train and test data becomes increasingly likely which suggests a similar phenomena could be happening with WebText.
- Common LM datasets’ test sets have between 1-6% overlap with Web- Text train, with an average of overlap of 3.2%. Somewhat surprisingly, many datasets have larger overlaps with their own training splits, with an average of 5.9% overlap.
- Overall, our analysis suggests that data overlap between WebText training data and specific evaluation datasets pro- vides a small but consistent benefit to reported results.
Discussion
- On reading comprehension the performance of GPT-2 is competitive with supervised baselines in a zero-shot setting. However, on other tasks such as summarization, while it is qualitatively performing the task, its performance is still only rudimentary according to quantitative metrics.
- While zero-shot performance establishes a baseline of the potential performance of GPT-2 on many tasks, it is not clear where the ceiling is with finetuning.
My Thoughts…
- GPT-2에 대한 내 한 줄 요약: 데이터와 파라미터 수를 엄청 늘려서 zero-shot transfer task에 해 보니 결과가 좋았음
GPT-3: Language Models are Few-Shot Learners (2020)
Abstract: Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions – something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3’s few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
Approach
- Our basic pre-training approach, including model, data, and training, is similar to the process described in GPT-2, with relatively straightforward scaling up of the model size, dataset size and diversity, and length of training.
- Our use of in-context learning is also similar to GPT-2, but in this work we systematically explore different settings for learning within the context.
Different Settings for Evaluation
- Fine-Tuning (FT): updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task.
- strong performance
- need for large dataset, poor generalization, exploitation of spurious features of training data
- Few-Shot (FS): the model is given a few demonstrations of the task at inference time as conditioning, but no weight updates are allowed.
- major reduction in need for task-specific data and reduced potentional to learn an overly narrow distribution
- results have been worse than SoTA fine-tuned methods and small amount of task-specific data still required
- One-Shot (1S): same as few-shot except that only one demonstration is allowed
- most closely matches how humans are communicated to
- difficult to communicate the content or format of a task if no examples are given
- Zero-Shot (0S): same as one-shot excpet that no demonstrations are allowed and the model is only given a natural language instruction describing the task
- maximum convenience, potential for robustness, avoidance of spurious correlations
- most challenging (even for humans)

Model and Architectures
- Same model and architecture as GPT-2 with the exception that we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer
- To study the dependence of ML performance on model size, we train 8 different sizes of model, ranging over three orders of magnitude from 125 million parameters to 175 billion parameters, with the last being the model we call GPT-3.
Training Dataset
- Processed Common Crawl and expanded version of WebText & other high-quality reference corpora
- To reduce contamination, we searched for and attempted to remove any overlaps with the development and test sets of all benchmarks studied in this paper.
Training Process
- larger models can typically use a larger batch size, but require a smaller learning rate.
- To train the larger models without running out of memory, we use a mixture of model parallelism within each matrix multiply and model parallelism across the layers of the network. All models were trained on V100 GPU’s on part of a high-bandwidth cluster provided by Microsoft.

Evaluation
- For few-shot learning, we evaluate each example in the evaluation set by randomly drawing K examples from that task’s training set as conditioning, delimited by 1 or 2 newlines depending on the task. K can be any value from 0 to the maximum amount allowed by the model’s context window, which is $n_{ctx} = 2048$ for all models and typically fits 10 to 100 examples.
Results
Language Modeling, Cloze, and Completion Tasks
- Language Modeling: new SOTA on Penn Tree Bank(PTB) by 15 points, achieving preplexity of 20.50
- LAMBADA (long range dependency): 0S setting 76% on LAMBADA, gain of 8% over previous SOTA
Closed Book Question Answering
- TriviaQA: 64.3% in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting. The one-shot result improves by 3.7% and matches the SOTA for an open-domain QA system which not only fine-tunes but also makes use of a learned retrieval mechanism over a 15.3B parameter dense vector index of 21M documents.
- WebQuestions: GPT-3 achieves 14.4% in the zero-shot setting, 25.3% in the one-shot setting, and 41.5% in the few-shot setting. This compares to 37.4% for fine-tuned T5-11B, and 44.7% for fine-tuned T5-11B+SSM, which uses a Q&A-specific pre-training procedure. GPT-3 in the few-shot setting approaches the performance of state-of-the-art fine-tuned models.
- Natural Questions: GPT-3 achieves 14.6% in the zero-shot setting, 23.0% in the one-shot setting, and 29.9% in the few-shot setting, compared to 36.6% for fine-tuned T5 11B+SSM.
- Overall, on one of the three datasets GPT-3’s one-shot matches the open-domain fine-tuning SOTA. On the other two datasets it approaches the performance of the closed-book SOTA despite not using fine-tuning.
Translation
- Since we increase the capacity by over two orders of magnitude from GPT-2 to GPT-3, we also expand the scope of the training dataset to include more representation of other languages (7%), though this remains an area for further improvement.
- By contrast, GPT-3 learns from a blend of training data that mixes many languages together in a natural way, combining them on a word, sentence, and document level. GPT-3 also uses a single training objective which is not customized or designed for any task in particular.
- each translation task improves performance by over 7 BLEU and nears competitive performance with prior work. GPT-3 in the full few-shot setting further improves another 4 BLEU resulting in similar average performance to prior unsupervised NMT work.
- GPT-3 significantly outperforms prior unsupervised NMT work when translating into English but underperforms when translating in the other direction. Performance on En-Ro is a noticeable outlier at over 10 BLEU worse than prior unsupervised NMT work.

Winograd-Style Tasks
- The Winograd Schemas Challenge [LDM12] is a classical task in NLP that involves determining which word a pronoun refers to, when the pronoun is grammatically ambiguous but semantically unambiguous to a human.
- Original: GPT-3 achieves 88.3%, 89.7%, and 88.6% in the zero-shot, one-shot, and few-shot settings, showing no clear in-context learning but in all cases achieving strong results just a few points below state-of-the-art and estimated human performance.
- More difficult: GPT-3 achieves 70.2% in the zero-shot setting, 73.2% in the one-shot setting, and 77.7% in the few-shot setting. For comparison a fine-tuned RoBERTA model achieves 79%, state-of-the-art is 84.6% achieved with a fine-tuned high capacity model (T5), and human performance on the task as reported by is 94.0%.
Common Sense Reasoning
- Overall, in-context learning with GPT-3 shows mixed results on commonsense reasoning tasks, with only small and inconsistent gains observed in the one and few-shot learning settings for both PIQA and ARC, but a significant improvement is observed on OpenBookQA. GPT-3 sets SOTA on the new PIQA dataset in all evaluation settings. Our analysis flagged PIQA for a potential data contamination issue (despite hidden test labels), and we therefore conservatively mark the result with an asterisk.
Reading Comprehension
- GPT-3 performs best (within 3 points of the human baseline) on CoQA [RCM19] a free-form conversational dataset and performs worst (13 F1 below an ELMo baseline) on QuAC [CHI+18] a dataset which requires modeling structured dialog acts and answer span selections of teacher-student interactions.
SuperGLUE 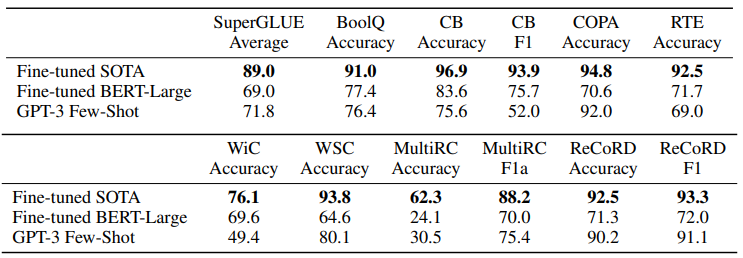
NLI
- On RTE, only the largest version of GPT-3 performs convincingly better than random (56%) in any evaluation setting, but in a few-shot setting GPT-3 performs similarly to a single-task fine-tuned BERT Large.
- These results on both RTE and ANLI suggest that NLI is still a very difficult task for language models and they are only just beginning to show signs of progress.
Synthetic and Qualitative Tasks
- Arithmetic: GPT-3 displays reasonable proficiency at moderately complex arithmetic in few-shot, one-shot, and even zero-shot settings.
- Word Scrambling and Manipulation Tasks: test GPT-3’s ability to learn novel symbolic manipulations from a few examples,
- SAT Analogies: GPT-3 achieves 65.2% in the few-shot setting, 59.1% in the one-shot setting, and 53.7% in the zero-shot setting, whereas the average score among college applicants was 57%
- News Article Generation: Human abilities to detect model generated text appear to decrease as model size increases: there appears to be a trend towards chance accuracy with model size, and human detection of GPT-3 is close to chance.

- Learning and Using Novel Words: A task studied in developmental linguistics [CB78] is the ability to learn and utilize new words, for example using a word in a sentence after seeing it defined only once, or conversely inferring a word’s meaning from only one usage.
- Correcting English Grammar

Measuring and Preventing Memorization Of Benchmarks
- GPT-3 operates in a somewhat different regime. On the one hand, the dataset and model size are about two orders of magnitude larger than those used for GPT-2, and include a large amount of Common Crawl, creating increased potential for contamination and memorization
- We initially tried to address the issue of contamination by proactively searching for and attempting to remove any overlap between our training data and the development and test sets of all benchmarks studied in this paper. Unfortunately, a bug resulted in only partial removal of all detected overlaps from the training data. Due to the cost of training, it wasn’t feasible to retrain the model. To address this, we investigate in detail how the remaining detected overlap impacts results.
- For each benchmark, we produce a ‘clean’ version which removes all potentially leaked examples, defined roughly as examples that have a 13-gram overlap with anything in the pretraining set (or that overlap with the whole example when it is shorter than 13-grams).
- We then evaluate GPT-3 on these clean benchmarks, and compare to the original score. If the score on the clean subset is similar to the score on the entire dataset, this suggests that contamination, even if present, does not have a significant effect on reported results.
Limitations
- notable weaknesses in text synthesis and several NLP tasks: On text synthesis, although the overall quality is high, GPT-3 samples still sometimes repeat themselves semantically at the document level, start to lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs.
- poor sample efficiency during pre-training
- whether few-shot learning actually learns new tasks “from scratch” at inference time, or if it simply recognizes and identifies tasks that it has learned during training
- A limitation associated with models at the scale of GPT-3, regardless of objective function or algorithm, is that they are both expensive and inconvenient to perform inference on, which may present a challenge for practical applicability of models of this scale in their current form.
- Finally, GPT-3 shares some limitations common to most deep learning systems – its decisions are not easily interpretable, it is not necessarily well-calibrated in its predictions on novel inputs as observed by the much higher variance in performance than humans on standard benchmarks, and it retains the biases of the data it has been trained on.
My Thoughts
- 본 논문만 해도 40장 정도 된다. 아주 아주 간략히 정리해놨다. 근데 사실 모델 architecture에 변화는 딱히 없고, setting 바꾸는 것과 다양한 task에 성능을 보여주는 게 논문의 절반 이상이기 때문에… 내가 생각하기에는 필요한 정보는 다 있다. 근데 정리 안 한 부분에 potential misuse, gender/race bias 등에 대한 얘기를 하는데 꽤 흥미로웠다.
- GPT-2와 비슷하게 데이터와 파라미터 수를 늘린 게 모델의 가장 큰 특징이라고 할 수 있다.
- 기존 benchmark task 외에 synthetic task가 좀 흥미로웠다. 어떻게 보면 이런 task 들이 더 인간에 가까운 언어 능력을 보여주는지 적합한 task가 아닌가 싶었다. Open AI는 어떤 특정 task 뿐만 아니라 더 general 한 AI, 결국 cognitive AI를 만드는 목표를 가지고 있다는 생각이 들었다. 인간이 task학습하는 방법과 비교한 것도 꽤 흥미로운 관점이라고 생각한다.
- 놀라운 성능을 보여주는 GPT-3 이지만 개인 연구자가 감당하기에는 너무 큰 모델이다. 웬만한 기업도 감당하기 어려울 정도의 사이즈인 것 같다. 저자들도 이 것을 모델의 한계점으로 인정하는 부분이다. 요즘 트렌드는 더 작은 모델로 더 좋은 성능을 요구하는 하는데, 트렌드에 좀 맞지 않는 모델이라는 생각도 든다. 하지만 어떻게 보면 그런 모델들과 궁극적인 목표가 아예 다르기 때문에 비교대상으로 삼는 게 옳지 않을 수도 있다. 자연스러운 language modeling 모델은 이렇게 파라미터가 커야하나? generation쪽에도 모델 사이즈를 줄이는 연구가 진행되고 있는지 찾아봐야겠다고 생각을 했다.