Abstract: Fine-tuning large pre-trained models is an effective transfer mechanism in NLP. However, in the presence of many downstream tasks, fine-tuning is parameter inefficient: an entire new model is required for every task. As an alternative, we propose transfer with adapter modules. Adapter modules yield a compact and extensible model; they add only a few trainable parameters per task, and new tasks can be added without revisiting previous ones. The parameters of the original network remain fixed, yielding a high degree of parameter sharing. (2019)
–
Paper Summary
Goal: In this paper we address the online setting, where tasks arrive in a stream. The goal is to build a system that performs well on all of them, but without training an entire new model for every new task. For this, we propose a transfer learning strategy that yields compact and extensible downstream models.
Transfer Learning Strategies
- Feature-based Tranfer
- Fine-tuning
- Adapter modules (proposed by authors): more parameter efficient that (1) and (2). Adapter-based tuning requires training two orders of magnitude fewer pa- rameters to fine-tuning, while attaining similar performance.
Adapters
- Adapters are new modules added between layers of a pre-trained network.
- Adapter-based tuning relates to multi-task and continual learning.
- Multi-task learning: results in compact models but requires simultaneous access to all tasks, which the adapter module doesn’t.
- Continual learning: learns from an endless stream of tasks–tends to forget previous task after re-training. Unlike adapter training, where tasks do not interact and shared parameters are frozen.
Adapter tuning for NLP
Properties of Adapters
- it attains good performance,
- it permits training on tasks sequentially, that is, it does not require simultaneous access to all datasets, and
- it adds only a small number of additional parameters per task.
- useful for context of cloud services
- To achieve these properties, we propose a new bottleneck adapter module. Tuning with adapter modules involves adding a small number of new parameters to a model, which are trained on the downstream task (Rebuffi et al., 2017).
- Adapter modules perform more general architectural modifications to re-purpose a pre-trained network for a downstream task.
- The weights of the original network are untouched, whilst the new adapter layers are initialized at random. The parameters of the original network are frozen and therefore may be shared by many tasks.
- Adapter modules have two main features: a small number of parameters, and a near-identity initialization.
- A near-identity initialization is required for stable training of the adapted model
- The total model size grows relatively slowly when more tasks are added.
Adapter Architecture 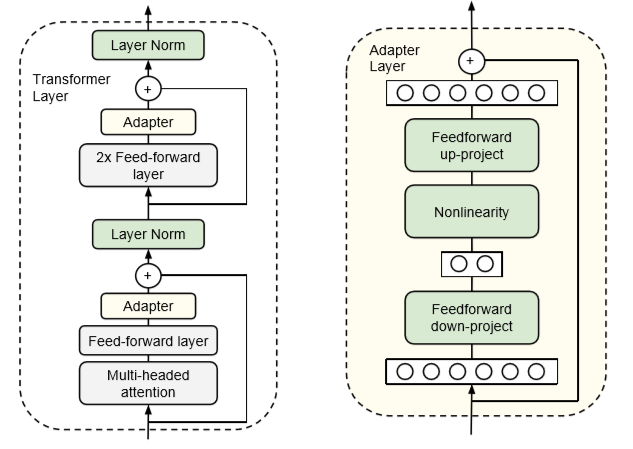
- The output of each sub-layer of transformer model is fed into layer normalization. We insert two serial adapters after each of these sub-layers. The adapter is always applied directly to the output of the sub-layer, after the projection back to the input size, but before adding the skip connection back. The output of the adapter is then passed directly into the following layer normalization.
- To limit the number of parameters, we propose a bottle-neck architecture. The adapters first project the original d-dimensional features into a smaller dimension, m, apply a nonlinearity, then project back to d dimensions.
- The total number of parameters added per layer, including biases, is 2md + d + m. By setting m < d, we limit the number of parameters added per task; in practice, we use around 0.5 - 8% of the parameters of the original model. The bottleneck dimension, m, provides a simple means to trade-off performance with parameter efficiency.
- The adapter module itself has a skip-connection internally. With the skip-connection, if the parameters of the projection layers are initialized to near-zero, the module is initialized to an approximate identity function.
Experiments
We show that adapters achieve parameter efficient transfer for text tasks. On the GLUE benchmark (Wang et al., 2018), adapter tuning is within 0.4% of full fine-tuning of BERT, but it adds only 3% of the number of parameters trained by fine-tuning.
GLUE benchmark
- We perform a small hyperparam- eter sweep for adapter tuning: We sweep learning rates in {3 · 10e5, 3 · 10e4, 3 · 10e3}, and number of epochs in {3, 20}.
- We test both using a fixed adapter size (number of units in the bottleneck), and selecting the best size per task from {8, 64, 256}.
- The adapter size is the only adapter-specific hyperparameter that we tune. The adapter size controls the parameter efficiency, smaller adapters introduce fewer parameters, at a possible cost to performance.
- Finally, due to training instability, we re-run 5 times with different random seeds and select the best model on the validation set.

- Adapter tuning is highly parameter-efficient, and produces a compact model with a strong performance, comparable to full fine-tuning.
Analysis
- First, we observe that removing any single layer’s adapters has only a small impact on performance. In contrast, when all of the adapters are removed from the network, the performance drops substantially: to 37% on MNLI and 69% on CoLA – scores attained by predicting the majority class. This indicates that although each adapter has a small influence on the overall network, the overall effect is large.
- Second, Figure 6 suggests that adapters on the lower layers have a smaller impact than the higher-layers. This indicates that adapters perform well because they automatically prioritize higher layers. One intuition is that the lower layers extract lower-level features that are shared among tasks, while the higher layers build features that are unique to different tasks.
- In our main experiments the weights in the adapter module were drawn from a zero-mean Gaussian with standard deviation 10 2, truncated to two standard deviations. We observe that on both datasets, the performance of adapters is robust for standard deviations below 10 2. However, when the initialization is too large, performance degrades, more substantially on CoLA.

My Thoughts
- 지금 adapter관련 실험을 하고 있는데 성능이 그닥 좋지가 않다. 이유는 여러가지가 될 수 있겠지만 논문을 다시 읽어보니 생각보다 많은 parameter tuning을 진행했다는 것을 알 수 있다. 나도 앞으로 adapter size나 training epoch을 조절해서 적절한 parameter를 찾아가야겠다. 그리고 논문 저자들은 구글에 있는 연구자들이기 때문에 google cloud tpu를 4개나 사용해서 학습했다. 하드웨어 차이에 성능차이도 당연히 있기 때문에 이 점을 감안하고 실험을 진행해야겠다.
- bottle neck 아키텍처가 페이퍼의 핵심으로 보인다. input을 feed-forward layer에 넣어주면서 사이즈를 줄여준다. 그러므로 학습되는 parameter이 줄어든다. 약간 attention이랑도 비슷하다는 생각을 했다. 어쨋든 내용을 함축해서 represent하는 방식이니까.
- 사실 task에 적용했을 때 큰 메리트는 잘 모르겠는데 (어차피 fine tuning할 때는 task마다 다르지만 학습이 그렇게 오래 걸리지 않는다… 아마 저자들은 cloud 사용을 위해 개발한거 같다) language transfer learning할 때는 확실히 차이가 있을 거 같다. 다음으로 읽을 논문은 바로 이 아키텍쳐를 language transfer learning한 것!